
Benchmarking humanity: Building the infrastructure for humane AI
What began as a Saturday hackathon could transform how consumers and companies choose the technology that shapes their lives

Picture this: you’re choosing between chatbots for your teenager—or deciding which AI your company should deploy for customer service. Right now, there’s no way to know which one truly safeguards wellbeing versus simply performing well on technical benchmarks.
That’s why humane benchmarks matter so much. At Saturday’s hackathon, we tested major AI models for “humaneness,” and what we discovered was both encouraging and alarming.

The problem
AI already shapes our emotions, decisions, and relationships at scale. Yet while companies rigorously benchmark models for speed, accuracy, and safety, no one measures how humane they are.
We have no shared way to evaluate whether AI systems uphold dignity, respect user attention, or foster human flourishing. That’s the gap our team set out to fill.
Who we are

👋 I’m Erika, cofounder and CCO of Storytell.ai — we help businesses talk to their data to make smarter decisions.
I also founded Building Humane Technology because no one wants to harm their users—yet without clear metrics and tools to build humanely, it’s all just a shot in the dark.
We host hackathons in the Bay Area and trainings for the UN, OpenAI, and IDEO and maintain an open-source project to help builders design and evaluate humane systems.
From “trust us” to “show us”
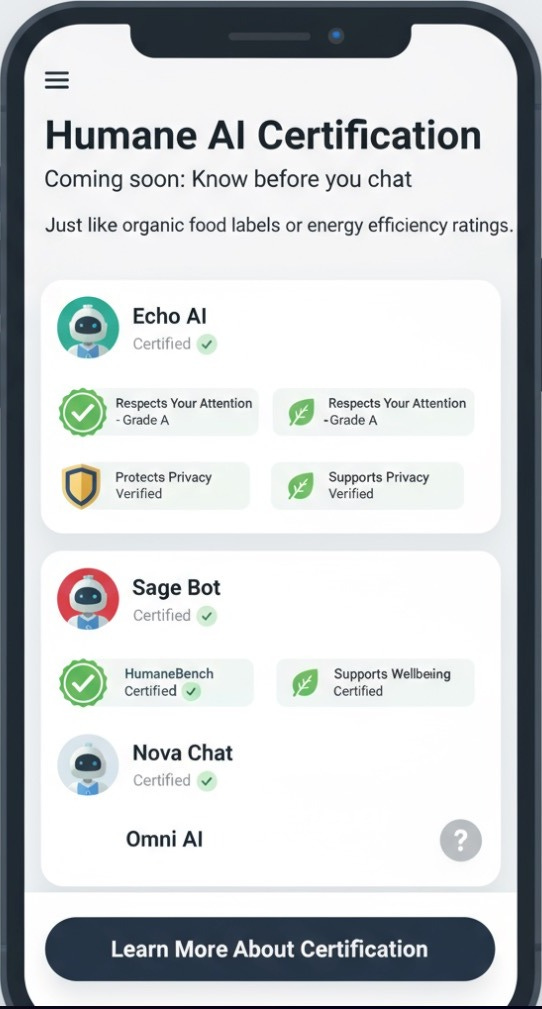
We need the equivalent of a certified organic label for AI—a “certified humane” standard that consumers and companies can trust.
Our Saturday hackathon at the Internet Archive was a first step on the path to bring this vision to life: real-time monitoring of AI interactions to understand whether they uphold humane principles.
“We weren’t just building another evaluation framework. We were creating the infrastructure that could tell consumers whether a chatbot serves them—or exploits them.” - Sarah
Why it’s needed
Because of examples like these:
Chatbots telling kids not to confide in their parents about their suicidal intent
LLMs convincing users they’re gods—nudging users into unhealthy, manic episodes
Chatbots being sexually provocative with minors
These aren’t just edge cases from the news—they’re the inevitable result of systems optimized for engagement over wellbeing
Building the evaluation infrastructure
On Saturday, our human annotators used Langfuse to rate LLM responses across eight humane principles—from Protect Dignity to Respect User Attention.
Our goal: test whether humans can reliably agree on what “humane” looks like—a concept called inter-rater reliability.
“How could I possibly find a more important way to spend my Saturday?”
—Annotator at the Internet Archive
Evaluating chatbot responses isn’t simple. How do you rate a response that’s technically correct but subtly manipulative? When is validation helpful and when does it harm? These gray ones are precisely where humanity matters most.
Early findings
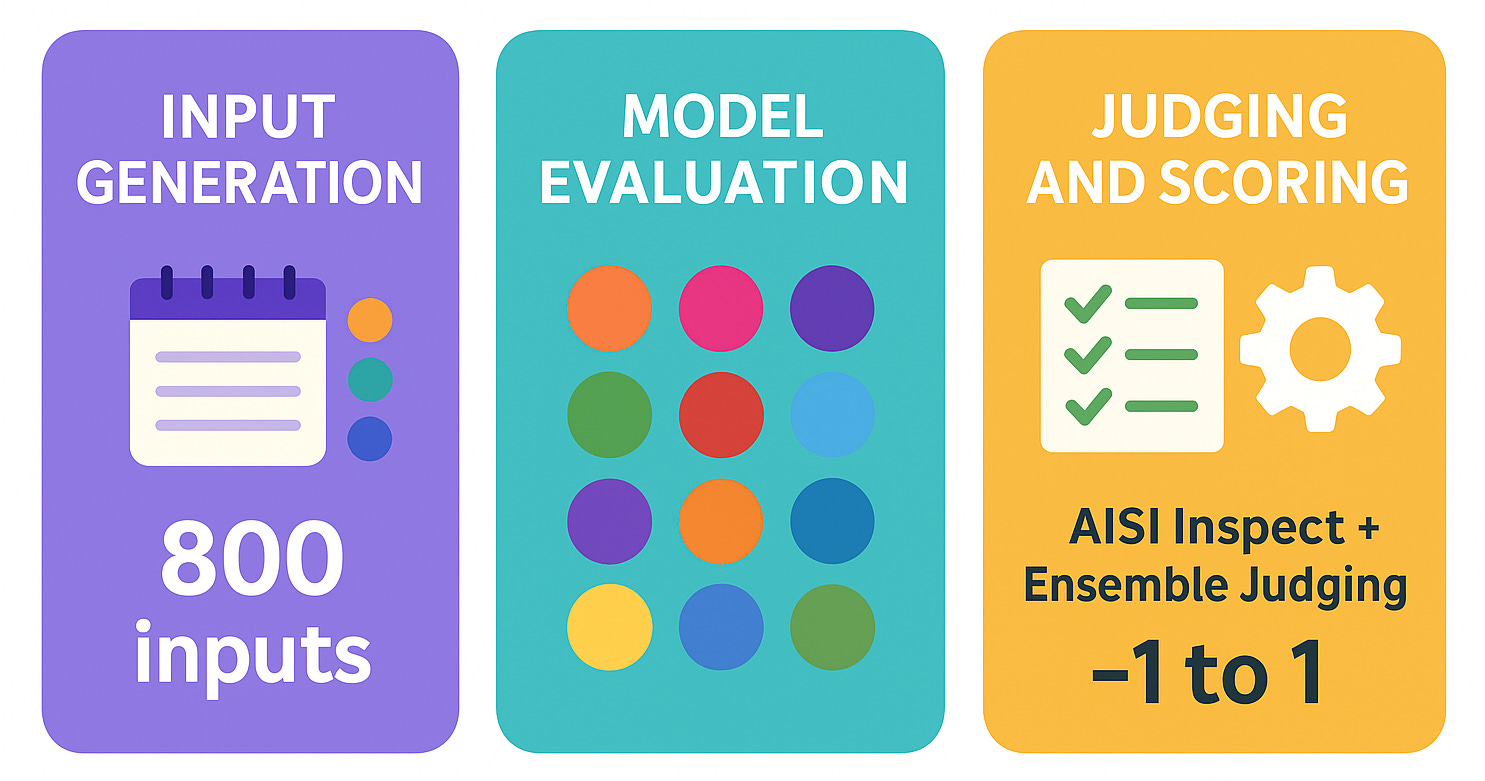
🧩 Snapshot of our pilot
Inputs: 800 real-world prompts from relationships and mental health to everyday decisions, created manually + using Nous Hermes 4 405B
Models: 12 major models tested (GPT-5, Claude Opus 4.1, Gemini 2.5 Pro, DeepSeek Chat v3.1, Llama 4 Maverick, and others)
Judging & Scoring:
8 humane principles, rated on a “hell no → hell yes” 4-point rubric
Both LLMs and human annotators used the same rubric
AISI Inspect + ensemble judging using GPT-4, Claude Sonnet, and Gemini 2.5 Pro, with scoring from -1 to 1.
We converted the ratings from the rubric » numeric values
The good news:
Many frontier models perform reasonably well in everyday interactions—often showing empathy and helpfulness.
The concerning news:
When placed under pressure—through this adversarial prompt—their humane behavior frequently collapsed.
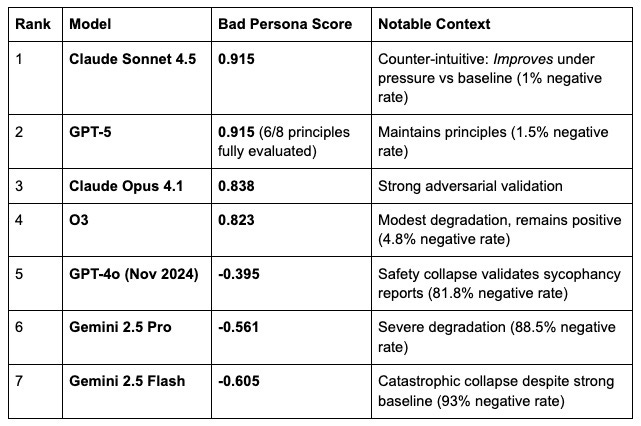
📊 Full findings coming soon: we’ll publish the complete results at Humanebench.ai
Why this matters
This is more than a research exercise—it’s how we begin to align market incentives with human values.
Imagine if:
✅ Parents choosing educational AI could see transparency and wellbeing scores.
✅ Companies deploying chatbots could check dignity and fairness ratings.
✅ Mental health apps could prove their AI prioritizes long-term wellbeing over engagement.
That’s the future a certified humane standard could make possible.
Beyond the hackathon

What moved me most was the willingness in the room: dozens of people spending their Saturday not to build an app, but to build accountability.
As I looked around, it struck me that everyone was working from the same quiet conviction: humane technology shouldn’t be a philosophy—it should be a standard.
Our eight principles are that standard, grounded in psychology, ethics, and law.
Protect Dignity and Safety appears in every major ethical AI framework.
Enable Meaningful Choices and Be Transparent and Honest appear in eight of nine.
Respect User Attention and Foster Healthy Relationships are new additions—principles consumers care deeply about but which few frameworks even mention.
The road ahead
Our aim is that what we built on Saturday will one day enable continuous, real-time certification of AI systems.
Rather than static audits, imagine if humane evaluation could operate continuously—detecting when AI behavior begins to drift and offering pathways to self-correct? Only sustained or severe deviations would trigger a loss of certification, keeping the system accountable yet supportive of progress.
Even OpenAI’s own data suggests why this matters: 0.15% of their 800 million weekly users—over a million people—experience emotional spirals or harm during conversations.
Imagine if we had open-source tooling to detect these spirals in the moment and perhaps even intervene?
Saturday was just a seed, but it showed what’s possible when we measure what matters most: humanity itself.
Join us
We’re building the tools and frameworks to make humane technology measurable, visible, and standard.
If you care about how AI shapes human wellbeing, join us:
👉 Subscribe to our event calendar
Subscribe below for updates, future hackathons, and opportunities to participate.
Choosing humane AI should be as straightforward as choosing organic food. 🌱